Reading Tiramisu in Czech and English: Robust Processing Speed Differences in Translation Equivalent Stimuli
Background: In contemporary sentence processing research, there is increasing interest in crosslinguistic differences (Siegelman et al., 2022). However, studies that compare sentence comprehension across languages using matched translation-equivalent stimuli remain relatively rare. A recent investigation (Chromý et al., 2023) uncovered notable differences in agreement attraction effects between Czech and English. Interestingly, a closer analysis revealed another pattern: native English speakers processed individual words in their language significantly faster than Czech speakers did in theirs. The present study seeks to explore this phenomenon in greater depth.
Method: We created 70 pairs of translation-equivalent sentences (Table 1), matched in length in words between Czech and English. These sentences included words that have identical graphical forms in both languages (e.g., tiramisu or Robert). While some of these words were declinable in Czech (e.g., judo, router, Adam), meaning they exhibited distinctive inflectional paradigms with varying endings for different cases (e.g., genitive forms juda, routeru, Adama), others were indeclinable (e.g., fantasy, origami, blues), retaining the same form regardless of case. Native speakers of Czech (N=176) and English (N=176) read these sentences, along with 48 fillers, in a self-paced reading task using a moving-window presentation. After each sentence, participants answered a yes-no comprehension question. Reaction times (RTs) for individual words served as the dependent variable, while the independent variables were language, word length (in characters), and declinability in Czech.
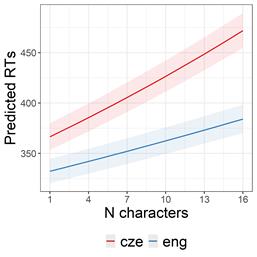
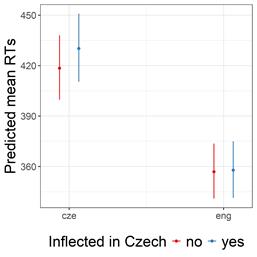
Results: A linear mixed-effects model with language and word length as fixed effects, and participant and item as random effects, revealed significant effects for both factors and their interaction (Figure 1). Specifically, (i) English words were processed faster than Czech words, (ii) longer words took more time to process, and (iii) the effect of word length was more pronounced for Czech. In a model focusing on identical words across the two languages, we found a main effect of language (English was faster) and an interaction between language and declinability (declinable words were processed more slowly in Czech than indeclinable ones; Figure 2).
Discussion: The results show robust differences in RTs between English and Czech. We argue that these differences are driven by the greater morphological complexity (i.e. efficiency) of Czech compared to English (Sadeniemi et al., 2008), which increases the cognitive load (i.e., prior) on Czech speakers even when processing identical words.
| Moje | teta | obvykle | pije | Bordeaux | a | další | francouzská | vína. |
| My | aunt | usually | drinks | Bordeaux | and | other | French | wines. |
| Table 1: Item example. |
References
Siegelman, N., Schroeder, S., Acartürk, C., Ahn, H. D., Alexeeva, S., Amenta, S., ... & Kuperman, V. (2022). Expanding horizons of cross-linguistic research on reading: The Multilingual Eye-movement Corpus (MECO). Behavior research methods, 54(6), 2843-2863.
Chromý, J., Brand, J. L., Laurinavichyute, A., & Lacina, R. (2023). Number agreement attraction in Czech and English comprehension: A direct experimental comparison. Glossa Psycholinguistics, 2(1).
Sadeniemi, M., Kettunen, K., Lindh-Knuutila, T., & Honkela, T. (2008). Complexity of European Union Languages: A comparative approach. Journal of Quantitative Linguistics, 15(2), 185-211.