Comparing the internal complexity of words: A pilot study on parallel texts in seven languages
The comparison of languages at the level of words and their internal structure is an intrinsic part of contrastive linguistics and language typology and has led, among other things, to the well-known morphological typology in terms of agglutination, fusion, isolation, etc. (Skalička, 1935; Sgall, 1986). Unlike syntactic research, where typological claims are refined and advanced on the basis of multilingual syntactically annotated corpora (in particular, Universal Dependencies, de Marneffe et al. 2021; cf., among others, Choi et al. 2022 or Levshina et al. 2023), theoretical insights related to the internal structure of words have not yet been explored on a broad data base. One reason is the inaccessibility of the words’ structure in machine tractable data.
Analysis of the internal structure of words in terms of their segmentation into morphemes as the smallest meaning-bearing units (so-called morphological segmentation) is available in printed dictionaries for some of the languages involved in the present experiment (Slavíčková 1975; Ološtiak et al. 2015; Kuznetsova and Efremova 1986; Tikhonov 1996). Information on the words’ internal structure is also available in some dedicated electronic resources. However, their utility for language comparisons is limited because they either provide reliable but mutually incompatible analyses for individual languages (e.g. CELEX, Baayen et al. 1995, or MorphoLex, Sánchez-Gutiérrez et al. 2018 and Mailhot et al. 2020) or, if they attempt multilingual coverage, the data for individual languages are of poor quality and inconsistent across languages (e.g. UniMorph, McCarthy et al. 2020; or UniSegments, Žabokrtský et al. 2022).
We report a pilot study in which we compare the complexity of words across seven typologically diverse languages (Czech, English, French, German, Hungarian, Russian, and Slovak). The study is carried out on the texts of Universal Declaration of Human Rights (Vatanen et al., 2010; originally retrieved from the UDHR Translation project at http://www.ohchr.org/EN/UDHR/Pages/Introduction.aspx), which, in each language, consists of a preamble and 30 articles sized from one sentence to several short paragraphs. The texts are POS-tagged using the UDPipe tool (Straka, 2018) (Straka, 2024) and segmented into morphemes (jointly with classification into roots, and inflectional and derivational affixes). Both morphological segmentation and morpheme classification were performed by neural tools using customized CNN-LSTM-CRF architecture (Ma and Hovy, 2016). The models were trained on semi-automatically extracted data. For Russian, we combined (Bolshakov, 2013) and (Tikhonov, 1996). The Slovak data come fully from (Ološtiak et al., 2015), while Czech data were extracted from the same source via a rule-based script. For Hungarian and French, we have used data from the 2022 SIGMORPHON shared task (Batsuren et al., 2022). For English and German, we have used CELEX and MorphoLex respectively, via UniSegments. We have annotated these automatically, using derivational and segmented data from UniMorph. We have augmented the datasets with UniMorph segmented data, combining the segmentations to add missing wordforms. The models achieve boundary-level accuracy between 89.3 % for Russian and 99.1 % for Hungarian.
Despite the relatively small size of the texts and the automatic processing, the analysis provides interesting insights. In all languages except Russian, single-morpeme words are the most numerous, followed by words with two morphemes, etc. Figure 1 documents that the tendency for word length to be inversely related to the word’s relative frequency (discussed as Zipf’s law) is more stable when word length is calculated in terms of morphemes than in terms of characters. The data also show differences in the number and diversity of different types of morphemes. There are correspondences between these metrics and languages’ genetic relationships (see Figures 2 and 3). The data thus exhibit the potential for comparing languages as for their preferences for different word-formation processes.
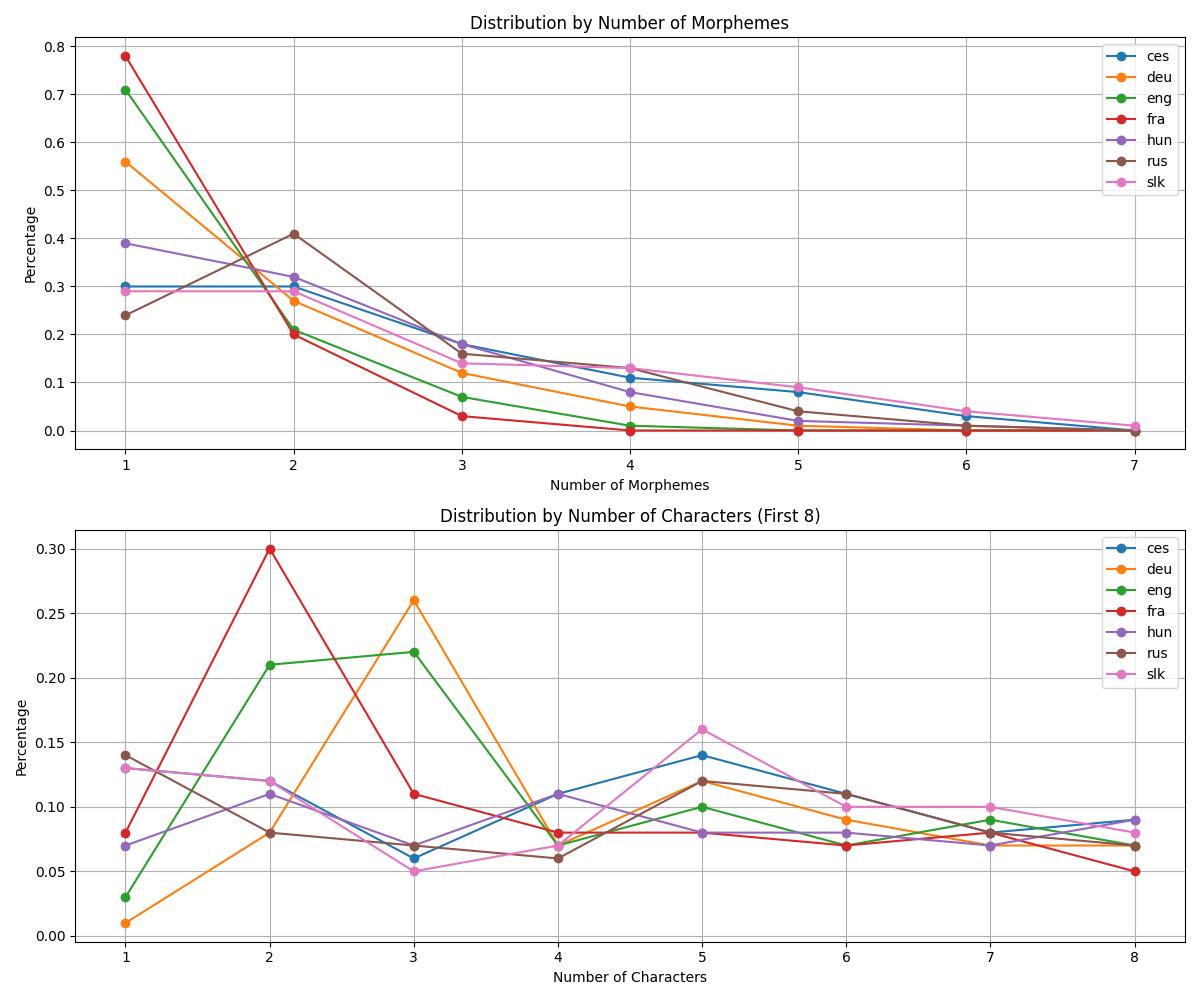
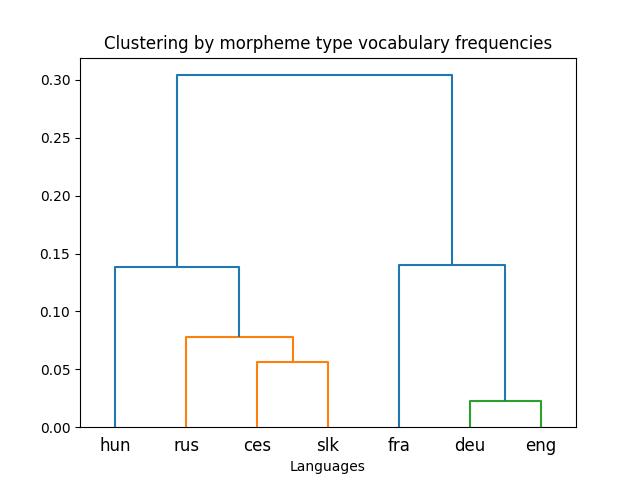

References
Baayen, R. H., Piepenbrock, R., and Gulikers, L. (1995). The CELEX lexical database (CD-ROM). Catalogue No. LDC96L14.
Batsuren, K. et al. (2022). The SIGMORPHON 2022 shared task on morpheme segmentation. In Nicolai, G. and Chodroff, E., editors, Proceedings of the 19th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, pages 103–116, Seattle, Washington. Association for Computational Linguistics.
Bolshakov, I. A. (2013). Crosslexica, the universe of links between russian words. Busyness Informatica,(3).
Choi, H.-S., Guillaume, B., and Fort, K. (2022). Corpus-based language universals analysis using universal dependencies. In roceedings of the Second Workshop on Quantitative Syntax (Quasy, SyntaxFest 2021), pages 33–44.
de Marneffe, M.-C., Manning, C. D., Nivre, J., and Zeman, D. (2021). Universal Dependencies. Computational Linguistics, 47(2):255–308.
Kuznetsova, A. I. and Efremova, T. F. (1986). Slovar’ morfem russkogo jazyka [Dictionary of morphemesof the Russian language]. Russkij jazyk, Moscow.
Levshina, N. et al. (2023). Why we need a gradient approach to word order. Linguistics, 61(4):825–883.
Ma, X. and Hovy, E. (2016). End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. In Erk, K. and Smith, N. A., editors, Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1064–1074, Berlin. ACL.
Mailhot, H. et al. (2020). MorphoLex-FR: A derivational morphological database for 38,840 French words. Behavior Research Methods, 52(3):1008–1025.
McCarthy, A. D. et al. (2020). Unimorph 3.0: Universal morphology. In Proceedings of the 12th Language Resources and Evaluation Conference. ELRA.
Ološtiak, M., Genči, J., Rešovská, S., and univerzita. Filozofická fakulta, P. (2015). Retrográdny morfematický slovník slovenčiny. Acta Facultatis Philosophicae Universitatis Prešoviensis: Slovník. Filozofická fakulta Prešovskej univerzity v Prešove.
Sgall, P. (1986). Classical typology and modern linguistics. Folia linguistica, 20:15–28.
Skalička, V. (1935). Zur ungarischen Grammatik. Nakladatelství University Karlovy, Praha.
Slavíčková, E. (1975). Retrográdní morfematický slovník češtiny: s připojenými inventárními slovníky českých morfémů kořenových, prefixálních a sufixálních.
Straka, M. (2018). UDPipe 2.0 prototype at CoNLL 2018 UD shared task. In Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, pages 197–207, Brussels, Belgium. Association for Computational Linguistics.
Straka, M. (2024). Universal dependencies 2.15 models for UDPipe 2 (2024-11-21). LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (ÚFAL).
Sánchez-Gutiérrez, C. H. et al. (2018). MorphoLex: A derivational morphological database for 70,000 English words. Behavior Research Methods, 50(4):1568–1580.
Tikhonov, A. N. (1996). Morfemno-orfografičeskij slovar’ russkogo jazyka. Russkaja morfemika (Morphemic-spelling dictionary of the Russian language. Russian morphemics). Shkola-Press, Moscow, Russia.
Vatanen, T., Väyrynen, J. J., and Virpioja, S. (2010). Language identification of short text segments with n-gram models. In Proceedings of the Seventh conference on International Language Resources and Evaluation (LREC’10), pages 3423–3430. European Language Resources Association (ELRA).
Žabokrtský, Z. et al. (2022). Towards universal segmentations: UniSegments 1.0. In Calzolari, N. et al., editors, Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1137–1149, Marseille. ELRA.