Improving Automatic Morphological Segmentation through Cross-Lingual Transfer Learning
Morphological segmentation refers to the process of breaking words into morphs, the smallest meaning-bearing units of language (Haspelmath, 2020). For example, the English word westernizes can be segmented as west-ern-ize-s. While the task is essential for linguistic analysis and downstream NLP applications, many languages still lack high-quality, morphologically segmented data.
Existing resources tend to fall into two groups: detailed but vocabulary-limited expert dictionaries, such as those for Czech (Slavíčková, 1975) and Slovak (Ološtiak, Genči, & Rešovská, 2015), and broader-coverage corpora like UniMorph (Batsuren et al., 2022a), which are often inconsistent across languages and less linguistically fine-grained.
To support the development of morphological segmentation tools for a wide range of languages, including those with only limited training data, we employ deep neural network models trained on character-level representations of words. These models are capable of learning generalizable patterns from annotated data, but their performance often depends heavily on the amount and quality of available training examples. A more detailed discussion of the model architecture, training setup, and performance is provided in Olbrich and Žabokrtský (2025).
To address this limitation and improve automatic morphological segmentation, particularly in low-resource settings, we adopt a cross-lingual transfer learning approach. This method allows us to transfer knowledge from one language to another, potentially reducing the need for large annotated datasets in each target language. Cross-lingual transfer learning has already proven highly effective in other NLP tasks, most notably in machine translation (Kocmi & Bojar, 2018), and offers a promising solution for segmentation as well.
In this study, we present results of cross-lingual transfer learning for seven European languages: Czech, English, French, German, Italian, Dutch, and Slovak. We focus exclusively on manually annotated datasets that provide complete morphological segmentation, allowing for linguistically meaningful evaluation across languages.
Five of the datasets were drawn from the Universal Segmentations project (Žabokrtský et al., 2022), which aims to create a harmonized multilingual resource by consolidating and standardizing 17 existing segmentation datasets across 32 languages. To this, we added high-quality manually segmented resources for Czech (Batsuren et al., 2022b) and Slovak (Ološtiak et al., 2015).
We investigate two key transfer scenarios. First, in a zero-shot transfer learning setup, the model is trained solely on a source language and then directly applied to a target language without access to any annotated data from the target. This simulates a fully low-resource setting, where no segmentation data is available for the language of interest. Second, we consider a limited-resource transfer scenario, where the model is first pre-trained on a source language and then fine-tuned using a small amount of target-language data, mimicking cases where some annotations exist but are insufficient for training a model from scratch.
As a baseline, we compare these transfer-based approaches to unsupervised methods such as Morfessor (Virpioja et al., 2013) and the Unigram Language Model (ULM) (Kudo, 2018), which do not rely on annotated training data but instead infer morphological structure from raw text using statistical patterns.
For evaluation, we report several standard metrics: word-level accuracy, as well as morph-level precision, recall, and F1 score. All datasets were randomly split into training and test sets, and results are reported on the test portion.
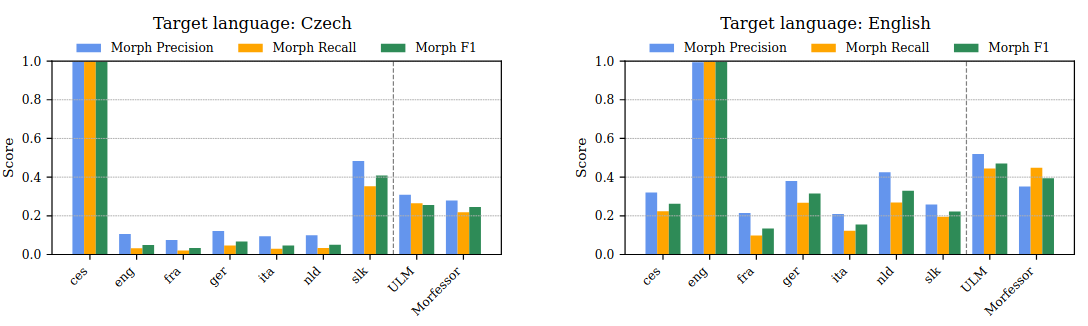
The first notable observation is that transfer learning yields the best results between closely related languages (see Figure 1). This is especially evident for Czech and Slovak (both Slavic languages) and German and Dutch (both Germanic languages). In some cases, moderate transfer was also observed between English and the Germanic languages (German and Dutch). Notably, for the Czech–Slovak pair, transfer learning outperformed unsupervised baselines, while for the German–Dutch pair, it achieved comparable performance. These results align with earlier findings reported in Olbrich and Žabokrtský (2025).
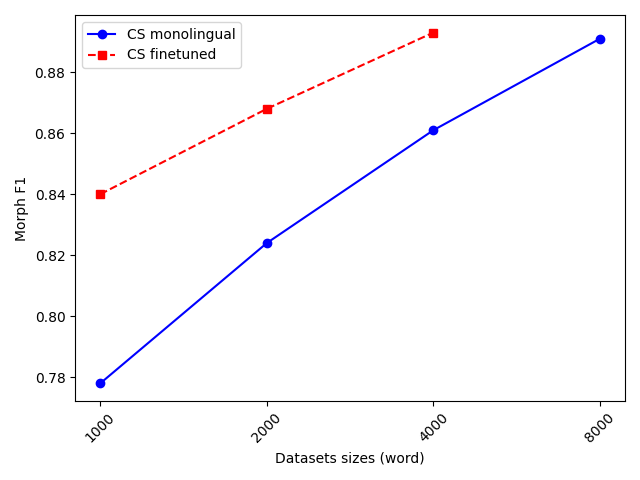
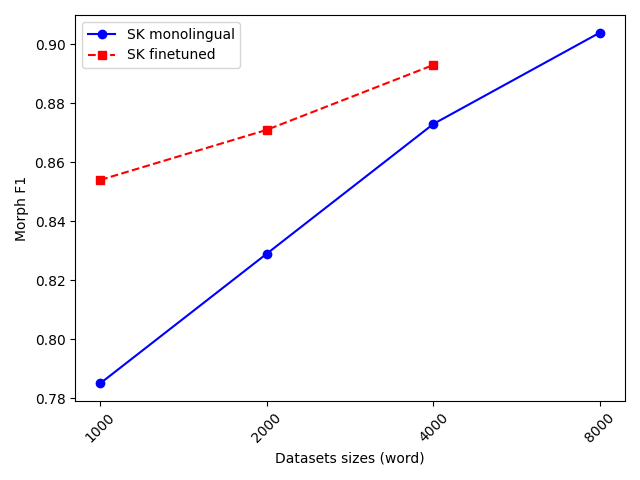
Second, in the limited-resource scenario, the performance of the cross-lingual model consistently improved with the amount of available target-language data. More interestingly, the benefit from transfer was in most cases greater than simply doubling the amount of monolingual training data. This effect is clearly illustrated in the Czech–Slovak experiments (Figure 2 and Figure 3).
These findings highlight the potential of cross-lingual transfer learning as a practical strategy for improving morphological segmentation in under-resourced languages.
References
Batsuren, K., Bella, G., Arora, A., Martinović, V., Gorman, K., Žabokrtský, Z., Ganbold, A., Dohnalová, Š., Ševčíková, M., Pelegrinová, K., et al. (2022b). The SIGMORPHON 2022 shared task on morpheme segmentation. arXiv preprint arXiv:2206.07615.
Batsuren, K., Goldman, O., Khalifa, S., Habash, N., Kieraś, W., Bella, G., Leonard, B., Nicolai, G., Gorman, K., & Ate, Y. G. (2022a). UniMorph 4.0: Universal morphology. arXiv preprint arXiv:2205.03608.
Haspelmath, M. (2020). The morph as a minimal linguistic form. Morphology, 30(2), 117–134.
Kocmi, T., & Bojar, O. (2018). Trivial transfer learning for low-resource neural machine translation. arXiv preprint arXiv:1809.00357.
Kudo, T. (2018). Subword regularization: Improving neural network translation models with multiple subword candidates. arXiv preprint arXiv:1804.10959.
Olbrich, M., & Žabokrtský, Z. (2025). Morphological segmentation with neural networks: Performance effects of architecture, data size, and cross-lingual transfer in seven languages. In Proceedings of the International Conference on Text, Speech, and Dialogue (TSD). Springer. (To appear)
Ološtiak, M., Genči, J., & Rešovská, S. (2015). Retrográdny morfematický slovník slovenčiny. Prešov: Filozofická fakulta Prešovskej univerzity v Prešove.
Slavíčková, E. (1975). Retrográdní morfematický slovník češtiny. Prague: Academia.
Virpioja, S., Smit, P., Grönroos, S.-A., & Kurimo, M. (2013). Morfessor 2.0: Python implementation and extensions for Morfessor Baseline. Aalto University.
Žabokrtský, Z., Bafna, N., Bodnár, J., Kyjánek, L., Svoboda, E., Ševčíková, M., & Vidra, J. (2022). Towards universal segmentations: UniSegments 1.0. In Proceedings of the Thirteenth Language Resources and Evaluation Conference (pp. 1137–1149).